前言
感谢数董会组织的这次活动,下文主要选自官微的分享文章,并对其中的错误拼写等进行了修改和整理。
现场实录
感谢数董会给大家组织了这么好的一个分享活动。首先自我介绍一下,我叫侯松,来自宜信,主要做大数据相关的事情。在这次分享之前,我先做一个小调查,在座有多少是做技术出身的?可以帮忙举个手吗?有专做大数据相关技术的吗?行,还挺多。这里面我会涉及到大数据很多的概念,还有一部分的细节,如果可以的话,我就稍微的覆盖一下。这个是我今天主要要讲的几个部分。首先介绍一下我们是谁;接下来是我们做的特别重要的三个产品,里面用到了很多大数据的技术,可能会给大家带来一些启发;最后,在做三个产品和相关技术的过程中,我们有哪些收获,可以给大家分享一下,让大家少走一些弯路。
首先我们是谁?宜信是世界上规模最大的P2P金融公司之一,做金融和P2P借贷的朋友应该都比较熟悉这个公司。接下来是我们团队,我们团队是姨搜团队,目前位于宜信的大数据创新中心。我们团队组建的目的就是为宜信整个公司提供风控数据服务和模型服务。接下来要讲的三个产品就是我们团队特别重要的三个支柱产品。最后我自己的一些经验,我自己做大数据相关系统有超过5年的实战经验,所涉及的系统包括很多开源的产品,如Hadoop、Hbase等等,还有在公司内部自己研发的很多分布式的大规模服务,比如接下来讲的语义网络、搜索引擎、还有工作流调度等。
接下来看一下我们做的三个产品。第一个是风控的搜索引擎,用法和我们平时用百度是比较像的,但是我们的目标是用来做风控。第二个是大规模的知识图谱,用来提供各种数据的融合和融合之后的数据的各种分析服务。最后一点是图谱搜索,这个是基于第二个大规模知识图谱来做的,是我们公司内部做反欺诈和风险控制用到的比较多的一个产品。
先看第一个,我们的风控搜索引擎。如果有一个人来找你借钱,借五万,借十万,他把信息告诉你,你怎么办呢?你肯定要看一下这个人是不是可信,他说的信息是不是真的。在互联网时代,大家肯定会想到到网上去查一下,这个人的手机号,他有没有发过一些什么贴子,类似于中介之类的,中介就可能骗你钱,或者他说就职于某公司,你一查,这个公司已经黄了,这里面就有比较大的风险。最早的时候,对一个P2P公司来说,他肯定是一些审核人员手动的去找,手动的找来信息之后,这些审核人员自己去判断。他拿什么判断,他就是拿自己的一些经验,他认为什么东西是对的,什么东西是有风险的,这样做的话是可以解决一部分问题,但是会带来其他的风险。这个过程其实非常依赖于审核人员自己的素质,如果P2P公司特别大,有几千个审核人员,那你就很难保证每个审核人员都能达到非常高的标准。
我们的风控搜索引擎就是基于刚才说的这些理论来出发的。我们会用爬虫去把这个人的信息放到网上各种各样的地方去查,查下来之后,我们会用一些机器学习来得到一些规则,来过滤爬虫抓到的信息,把无效信息扔掉,把有效信息提取出来,加一些标注。接下来,拿到这个信息之后,我们会把这个信息排序。比方说现在有一个借贷黑名单,他在上面出现了,肯定是特别重要的,类似这种信息我们会把它排在前面。我们的风控搜索引擎已经融合进整个的信审流程。这样做什么好处?所有人的效率都提高到一个非常高的水平上,很多的时候就不需要人工去查了,他只需要看前两页,前两页的信息里面是不是有标注他有问题的数据,这个时候整个的效率和风控水平就会有非常大的提高。
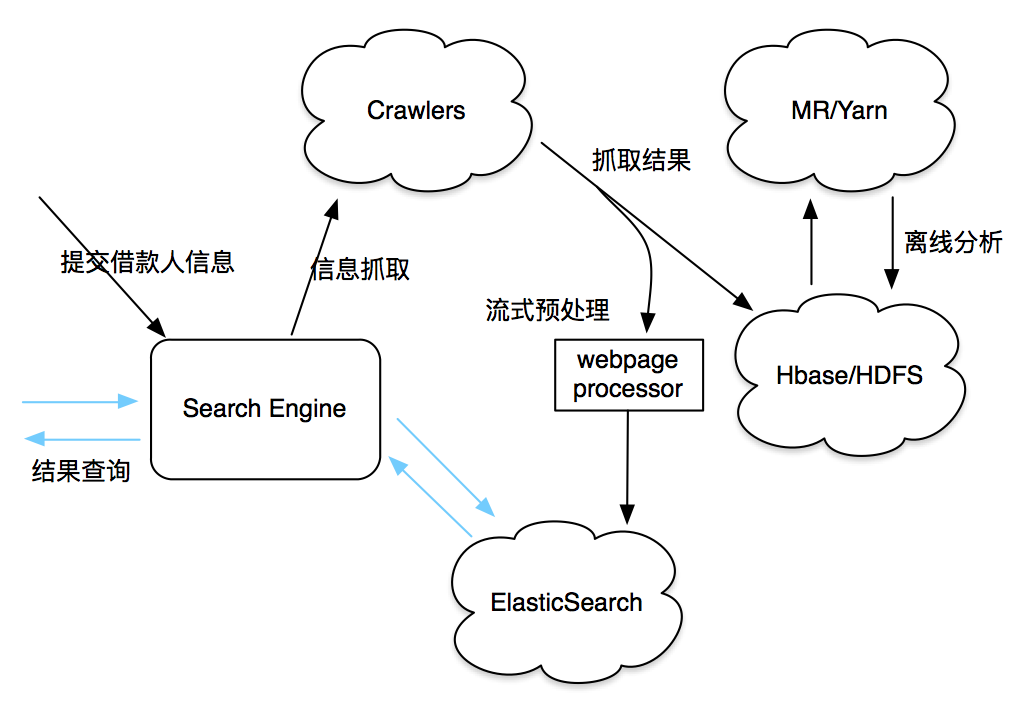
这个是一个比较简略的大概的流程图,技术人员可能会比较清楚。大概说一下,首先是提交借款人的信息,提交以后,我们放在爬虫上,一部分离线的分析,一部分在线的处理之后,发给ES,让ES进行它自己的HDFS,把它自己的判断程序,比如刚才讲的过滤、一些排序的规则放在Search Engine,之后所有的查询都是通过Search Engine。拿了数据之后,在Search Engine里面自己去做过滤、做排序,整个流程现在走下来的话在一到两分钟就可以完成。一到两分钟,这是什么概念呢?之前,我不说具体时间,就是我们的信审人员可能是这么一个状态,一个单子来了之后,我们要等信审人员空出时间来等这个单子,现在倒过来了,信审人员在那儿等单子来,这样就可以看出来效率的差距。
刚才说到风控搜索引擎,现在看一下大规模的知识图谱。这个东西是用来做什么的?出发点是这样的,我们认为风控的一个核心能力,就是它能从纷繁复杂的各种数据中,找出和这个人或者公司相关的信息,找到信息之后它又得进行交叉验证,还能用验证后的信息进行风险程度评估。这么说起来简单,但是有一点特别难,数据种类是特别多的,特别是在我国,各种数据,不管是政府的数据或者是公司数据,中间的差别非常大。首先可能非常难获取,获取到之后,你如何去用它,也是一个非常难的事情。比如有一个黑名单的数据库,有的可能就给你一个excel或者sql文件,如何用它是一个非常大的问题。我们设计这个大规模的知识图谱就是为了解决这个问题。我们是怎么解决的呢?我们的知识图谱是利用传统语义网的一部分原理。语义网是个什么东西?比方说你上网看一个网页,上面可能就是一些文字,人能理解,但是机器很难理解的,但是如果加上一些标签,这个网页里面提到谁谁,这个谁谁有什么手机号之类各种信息,这种信息就可以认为它是包含语义的,这种带语义的网页形成的网状图结构,就是一个语义网。
我们用的语义网的部分原理,就是把各个数据源的数据,不管它是什么类型的格式,都能转移、融合到同样一个平台下,这样所有的数据都进入到同一个平台,再之后所有的流程都是相同的了。比方说我这个流程已经打通了,现在有十个数据源,又找到五个新的数据源,我只需要把这五个数据的数据定义,写好之后放进去,之后所有的流程我都不要再改,所有的都是一致。这个看上去特别牛的一个东西是在什么上面做的呢?我们是基于很多的开源软件去做的,为什么要用Hadoop、Hbase这些环境,是因为我们的知识图谱非常大,TB级别的存储和计算,简单的单机软件是无法解决的。除了开源环境,我们还提供了很多的工具,来帮助开发人员和最终的用户,更好的用我们这个知识图谱。
这就是知识图谱。接下来分成四点详细的说一下。首先我说一下知识图谱是一个什么概念,刚才提到是基于语义网,怎么基于语义网的过程。第二个知识图谱由哪些东西组成。第三个是这些东西我们是怎么把它实现出来的,实现出来之后又怎么能保证它是非常高可用的、可扩展的、高性能的。最后,有了这些做的各种各样的技术,我们带来了什么样的能力,我们能用它做什么事情。
首先是一些最基本的概念。数据是一个什么东西,大家可以简单认为它就是一条信息。举一个例子比方说A是B的朋友这么一个信息,我们可以怎么来表示呢,可以写到文本文件里面,就是一句话,“A是B的朋友”,这个只有人能理解。我们也可以用一些定义好的数据库表,一张表有两列,第一列是第二类的朋友,其中一行,第一列是A,第二列是B,很明显A是B的朋友。但是最简单、最直接的可能就是我们这种三元组这种subject-predicate-object这种主谓宾的形式来表示,其实就是语义网中经常见到的一种数据表现形式。我为什么用这三元组,有什么好处?因为可以随意扩展的,这个predicate,可以是任意的一种定义,可以是我们商量好的一种定义形式,它的扩展和导入导出的能力都特别强大。这样的三元组的形式,使得知识图谱具有非常强大的表现能力和扩展能力,以及一些knowledge-based reasoning。这个例子待会儿可以看到,利用reasoning可以从现有的知识去推出很多新的知识出来。知识图谱有些什么特点?它是以entity为中心的。举个例子,人就是一个entity,人有他自己的属性,比如名字、电话、身份证。他还有各种人和人的关系,包括他认识谁,谁是他的boss等等。
第二个特点是它的schema非常的灵活。举个例子,如果说之前没有做过房贷,这个时候我要把房贷的信息加进来,房贷肯定是一种贷款,它又包含了房子。我可以直接重用之前关于通用贷款的所有工具和模型,然后添加进这个房屋本身的信息,就形成了房贷自己的数据格式。最后一点,可以无缝重用已有元数据。这个就是比较有意思的一点。语义网其实已经做了很多年了,它现在已经有很大的成果在里面,如果大家去看的话,网上有很多的开源的各种数据,比如最简单的有DBpedia,FreeBase,WordNet之类的。我举一个例子,比如说DBpedia是个比较权威的数据源,它里面有奥巴马,奥巴马是美国的总统。这句话就体现在DBpedia里,我只需要把DBpedia全部导到我的知识图谱里面,我的知识图谱就拥有了所有DBpedia的数据。WordNet里有英文比较常用的词语的解释,加入到我们的知识图谱之后,知识图谱就拥有了所有英文单词解释的能力,这个是一个非常强大的功能。
刚才的定义之上,我们是如何去划分知识图谱的各种体系,能够让它更加的健壮、更加的有效。首先是schema元数据,应该怎么去定义schema,能够让它更准确、无歧义。第二个我们拿到数据之后如何去转换,如何从外部的数据形式转换到我们内部的知识图谱的数据形式,有了这些数据之后,数据之间的关联关系是如何建立的,有了这个关系之后,我们如何用这些关系和拿到的数据进行一些智能化的、自动化的推理。最后,我们肯定是需要提供很多简单的工具,来帮助大家去用好这个知识图谱。
接下来我详细的说一下,首先是元数据的定义和描述。我们这里的元数据是基于语义网的,语义网有很多的定义,我们这个地方是基于RDF schema和OWL,还加入了我们自己定义的一些功能。举一个例子,比方说一个人的身份证,身份证号是有特殊的格式,不是所有的数字串都能当身份证,为了这些格式我们就在schema里面加入了一些规则。第二个要建立一个元数据委员会,评审确保正确性。这个是什么意思?因为每个人对同一事物的描述是会不一样的,比如说身份证号,可以是IDNumber,ID_number,或者ID_card,可以有很多的名字。我们需要有一个人或者是一个委员会来最后确定哪个描述是对的,哪个是错的。最后是自动化导入的方式,刚才我提到了,可以从各种现有的数据源中导入新的元数据。
数据的获取和转化,关于数据的获取和转化可以考虑这三个方面:第一是数据的获取形式。我们可以被动的接收数据,比如我起一个服务他发给我,或者我主动的通过爬虫到网上去抓,或者把数据库开放给出来,我们到数据库里面去搜索。当然还有很多其他的形式,比方说别人离线扔给我一个黑名单,我把这个黑名单也转换成我们的知识图谱的数据;第二,它的格式。它的格式可能是一个网页,也可能是我们拿回来的excel数据表。不同的时效性是不一样的,有些是需要实时的,有些可能通过机器学习,学到了风险列表,这些数据对时间要求就不是很高。这三个方面的每一种可能性我们都是支持的。
然后就是数据间关系的确立。刚才说了,知识图谱是以entity为中心的,这个entity之间是有关联关系的。关联关系可以分成两种,显式的关联关系和隐式的关联关系。举个例子,显式的关系,有个人过来借钱,他说他联系人是谁谁谁三个人,这4个人就有“联系人”这种显式关系。隐式的关系就是我们通过一些匹配规则或者机器学习去算出潜在的关系,这个关系会更加复杂和多样。举个例子,还是这个人过来借钱,他说他手机号是什么,身份证是什么,但是我在网上之前抓到过一个人,这个人之前发过一个贴子,手机号是什么。然后我们通过某个规则看到这二人特别像,“特别像”就是一种隐式的关系。如果我们能找到这种隐式关系,那我们很有可能把这个借款人拒掉,因为他有可能是一个借款中介,但是如果只看显式的关系我是找不到。第四个,有了刚才的显式和隐式的关系,我如何提高系统的智能。我们的知识图谱的schema是基于语义网来做的,语义网发展了很多年,已经有很多推理工具。给大家举个例子。比如说朋友关系,它是传递的,就是可逆的。这个时候,A是B的朋友,B是C的朋友,我再通过朋友关系这种特性,这三个人俩俩之间互相都是朋友,这个就是通过提高系统的智能能够得到潜在的关系。刚才说的是非常简单的例子,各种复杂的例子也有很多。
最后,说了知识图谱有那么强的功能,需要给用户非常好用的接口,让他非常快速方便的使用起来。我们的工具可以分为三大类,第一类就是数据源之间的同步,需要各种导入导出的工具。我们还有非常灵活多样的API,如果说有人要在我们的知识图谱之上做个应用,他可以非常方便的用到我们知识图谱里面的各种功能。最后也是比较有意思的一个工具,支持强大语法的查询引擎,可以把非常复杂的业务逻辑转到物理引擎上执行。可以把它类比成关系型数据库的Sql查询语句。
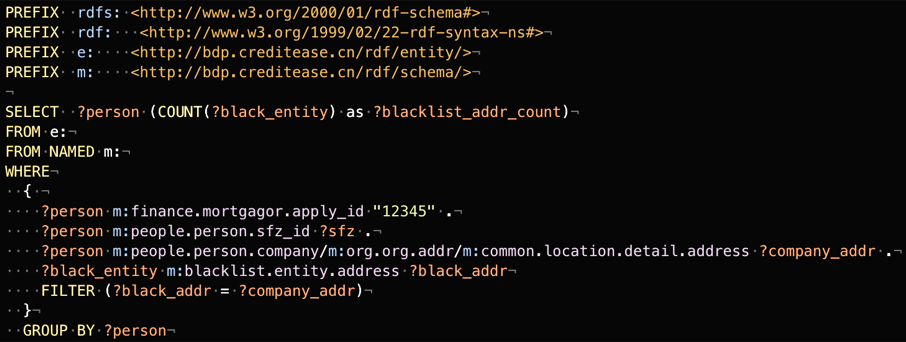
接下来给大家看一个查询语句的例子,上面四行可以先不管,如果只看这四行是不是有点像Sql语句。这个语句的意思是,有一个人是一个变量,这个Person的申请ID是12345,他的公司的详细地址是不是在黑名单出现过,如果有出现的话,算一下出现了多少次。这个语句其实是比较像自然语言了,不管是研发人员还是数据分析人员,他要写出这种语句是特别容易的。除了这一种即时查询之外,我把这一行删掉,如果只看这三句的话,是要做什么呢?是看所有人的公司地址在黑名单里面出现过几次,这样获得一个分析型的查询,能大概看出我的黑名单上的地址信息在借款人的公司地址上有多大的作用。除了内置的功能之外还可以进行拓展,比方说我们拿自然语言来分析,去看这两个地址有多大的匹配度。注意一下,这里的黑名单就不仅是我们宜信自己的黑名单了,可以是爬虫抓过来的,可以是合作第三方共享来的,也可以是我们机器学习得到的。不管是哪种来源,在这一条语句中就全部囊括了,非常的方便。
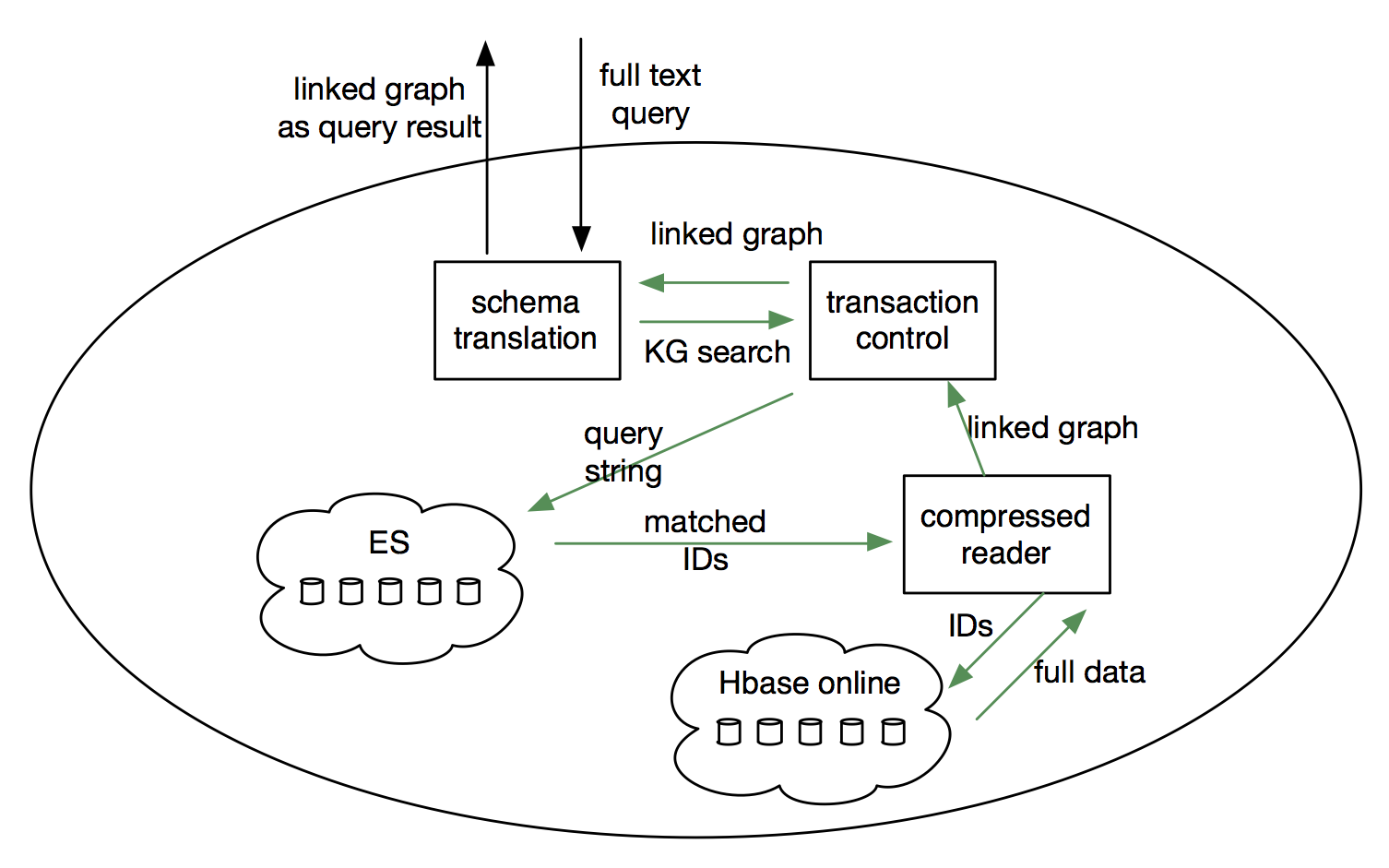
刚才说了我们知识图谱的五个体系组成部分,我们是如何去把它实现出来的?我们肯定不能停留在理论的层次上,要实现它,这四个基本要领肯定要支持的。首先知识图谱是一个图,这个图是支持离线分析和在线服务,同时又必须是大规模可水平拓展的图数据库。第二点,我们图库里面有很多的半结构化的数据,比如网页里抓的是帖子之类的数据,我们需要全文检索能力,这个全文检索就是类似于在上面跑了一个百度。第三个,它的时效性特别强,并且支持实时的写入。实时写入并不是说拿一个东西塞到这个数据库里就完了,之前有一系列的分析任务去通过,是全流程的,而不是简单写数据库而已。最后为了节省计算资源,提高性能,透明的压缩是要支持的。
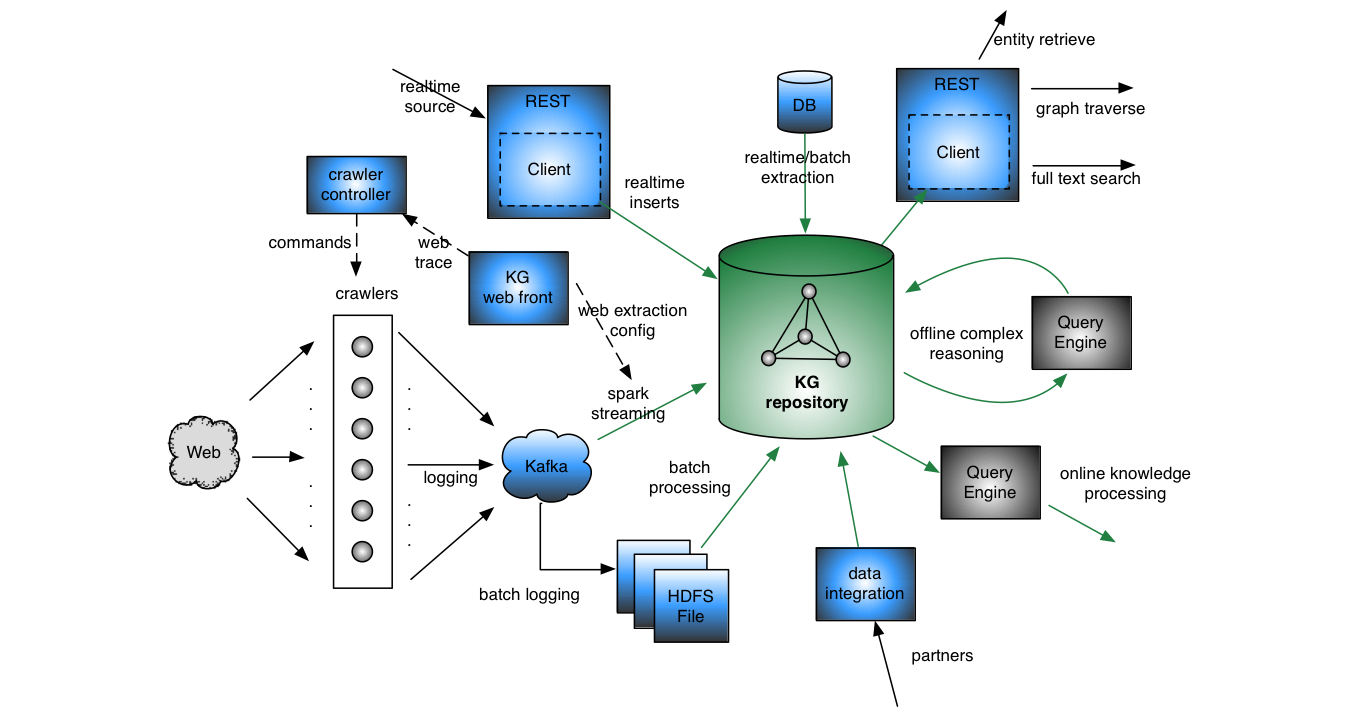
接下来看一下,这个就是我们知识图谱整个体系运作的大概样子。中心就是知识图谱的图数据数据库,它是分布式图数据库。它的数据有几个来源,一个是数据库来的,它可以是实时的流入的数据,也可以是网页抓的数据,或者说别人离线提供给我的某一个黑名单的数据。数据流出有这么几地方,一个是它可以通过在线服务,在线服务待会儿有一个例子可以看到,也可以通过刚才说的查询引擎,实时的读取或者跑离线的任务。
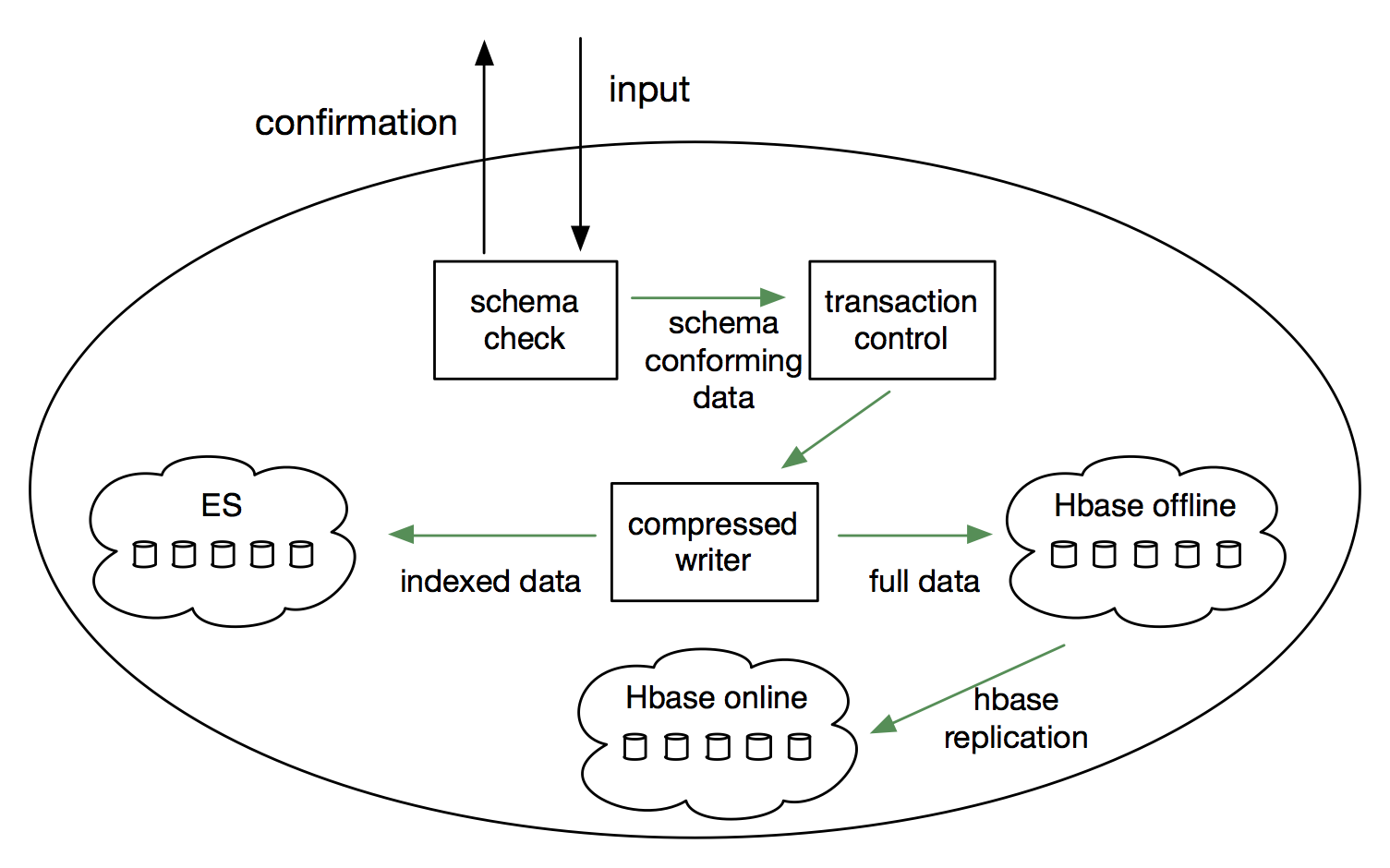
这个就是刚才看的中央分布式图数据库的样子,这个流程写的是一个数据写入的流程。数据写入流程就是它的流入进行一个schema check,检查它如果符合的话,会一路往下流,需要走全文检索的数据就可以放到ES里面,非全文检索的数据会通过一个离线的Hbase复制给在线的Hbase,这个过程都是自动完成的。如果大家用Hbase比较多的话,离线分析的集群和在线服务的集群是要分开的,要不然会有各种各样的稳定性问题。
刚才看了写入,现在看一下读取。全文检索的读取过程,我会把外部的请求转成我们知识图谱里面的schema查询的请求,然后再把这个请求转成ES的查询,然后去online的集群里面把这个数据取出来再解压反回去,这是一个在线服务的例子。如果是一个离线的查询,它就不走这个了,它可以直接去读离线的Hbase,这样会进行不同类别访问的区域隔离。
刚才说了那么多,用了两年的时间把这个东西开发出来,开发出来它有什么作用呢?简单的说有这么四点:
- 可以无缝的融合任意数据。只要你把数据给我,告诉我这个数据是什么,我就能把它非常清晰地和所有的数据整合在一起。在之后的各种离线、在线分析都是同样的流程,这个就为我们进行数据分析提供了非常强有力的帮助。
- 它是基于语义网的。每一个数据都会有非常丰富的语音信息,语义信息其实就是一个自解释的,所有的分析人员都能很快看懂。在知识图谱里面,它自己就描述了自己,你就没有必要特别费心的到处去问,能让数据分析人员特别快地开展自己的工作。
- 它的数据都是有网状连接的。这些数据我其实可以看到很多的隐含信息,接下来我们看到的第三个产品,就是很大程度上用到的这个能力。
- 就是查询引擎。刚才提到查询引擎的例子,这个给数据人员和数据分析师提供了非常方便而强大的分析能力,它既能在毫秒级返回即时查询,可以进行在线的服务,也可以支持大规模离线分析。现在我们知识图谱这四点都是可以做到的。
刚才说了一下我们的大规模知识图谱,它的基本概念是什么呢,它由哪五部分组成,我们是如何实现的,最后是有了这个知识图谱之后,我们拿它能干什么。这个说起来是比较枯燥的,里面还有很多的细节没有展开。接下来给大家看一个我们实际用到知识图谱的例子,就是这个图谱搜索。图谱搜索是什么?图谱搜索就是我们基于知识图谱开发的线索分析平台,现在主要的应用是反欺诈和部分审核人员,它广泛的应用于各种欺诈案件的识别和规则的发现。我给大家录了一个小的录像,里面做了一些处理,防止信息泄漏,大概能看懂是什么意思。这边是一个人,他通过各种信息关联到很多其他的人,其他的人再通过各种信息,他可以无限制的扩展,我们图谱搜索就可以知道这个人通过这个信息扩展出来,但是这个信息其实前后是不一致的,或者有什么其他的各种潜在的问题,我们这边就会有各种的形式标出来,标虚线,加各种颜色等,会有不同的类别。不同错误的分析类别,会有不同的标识。这个让审核人员和反欺诈人员非常方便的看出一种新的作案类型,谁和谁,是怎么发生关联的,之后我们可以在审核阶段就直接把他滤掉。
我们刚才主要讲了这三个,一是风控搜索引擎,这个是非结构化的数据,就是网上的各种数据,主要还是给人看的。二是大规模的知识图谱,既可以让机器来进行学习,提供服务,也可以由人来进行分析,识别它的风险。最后,基于知识图谱做的图谱搜索,这个能很大的帮助反欺诈人员来识别潜在的风险。
当然我们做的这一系列产品不是说只能用在风控上,我们可以用的地方是非常多的。举一个例子,比方说公安部要查某一个在逃的嫌疑犯,如果说他有大规模的知识图谱和各种产品的话,这个时候他就可以把这个人的信息放在这个上面去搜,在逃的嫌犯肯定是有一些固定的pattern,他不敢坐飞机或者其他,经常在什么地方出现。这个时候我就可以把pattern做成一个查询语句或者一些学习的程序,拿到一个知识图谱里面去找。最近美国一个特别火的公司叫做Palantir,大家可能听说过,Palantir要做的东西其实和我们特别像,当然他们内部是怎么做的暂时还没有太多的分享出来。接下来,我会在近期把这些相关的产品核心的代码开源出来,让大家都能看到。感兴趣的朋友,可以共同来提高系统的能力。那么我们有了什么呢?有了开源的Palantir。
在这两年多的时间内,我们做了很多很多的事情,在做这些事情的过程中,我们得到了一些我们自己的收获,现在跟大家分享一下。大数据的风控在前几年,是炒的比较火的一个概念。现在我们可以看到,它其实不是一个虚幻的概念了,我们可以在上面做很多事情。刚才我说到的一些事情并不是说做到了完美,做到了极致,我们接下来还有很多的事情要做,很多的路要走。
第二个说给研发人员听的,研发人员有一些偏向于深入研究的,有一些偏向广泛涉猎。我建议大家在广泛涉猎和深入研究都要有,集百家之所长,然后才能创造性的解决现实的问题,同时还能比较有创建性的提出新的问题,并给出一些好的思路。如果说我只有Hadoop的经验,没有语义网的概念,我就不能做出来前面说的大规模知识图谱,它可能只是停留在某些人脑海中。
最后一点,因为数据的融合和使用变得越来越简单,不管是我们这套系统将来开放出来给大家共同使用,还是各家有各家类似的产品,它肯定是变得越来越简单、越来越容易的。现在还有数据壁垒和数据获取的困难,但确实是在好转的。如果说大家有各种渠道的话可以及早的布局来获得这些数据,长久看来,在互联网金融或者说是更广的领域上可能会有更大的发言权。
行,我的分享就是这些,下面是我的邮箱,大家感兴趣的话可以给我发信或者可以去参观。
PPT
PPT 在这里