在我们的Hbase集群中,有时存在有些 RegionServer 因为不能继续往 HDFS 中写入 WAL 数据而导致异常退出,相应的异常如下:
2016-08-06 03:45:42,547 FATAL [regionseerver/c1-hd-dn18.bdp.idc/10.130.1.37:16020.logRoller] regionserver.HRegionServer: ABORTING region server c1-hd-dn18.bdp.idc,16020,1469772903345: Failed log close in log roller
org.apache.hadoop.hbase.regionserver.wal.FailedLogCloseException: hdfs://ns1/hbase/WALs/c1-hd-dn18.bdp.idc,16020,1469772903345/c1-hd-dn18.bdp.idc%2C16020%2C1469772903345.default.1470426151350, unflushedEntries=61
at org.apache.hadoop.hbase.regionserver.wal.FSHLog.replaceWriter(FSHLog.java:988)
at org.apache.hadoop.hbase.regionserver.wal.FSHLog.rollWriter(FSHLog.java:721)
at org.apache.hadoop.hbase.regionserver.LogRoller.run(LogRoller.java:137)
at java.lang.Thread.run(Thread.java:745)产生这个FATAL之前,大量的 java.io.IOException:Failed to replace a bad datanode on the existing pipeline due to no more good datanodes being available to try. 记录在其日志文件中。 从该异常抛出的message来分析, 则意味着在 RegionServer 输出这样异常的那刻起, 在 HDFS 集群范围内找不到一例可用的DataNode来加入到当前的 Stream Pipeline 中。 然而事实上,我们当时的 HDFS 还在正常提供着数据的增删改查功能,并非没有正常的 DataNode 可用。
继续分析_RegionServer_的日志,在无可用_DataNode_之前,RegionServer 会不断尝试与新的_DataNode_重建Stream Pipeline,毫无例外, 这样的尝试都失败了:
2016-08-06 03:44:29,320 INFO [DataStreamer for file /hbase/WALs/c1-hd-dn18.bdp.idc,16020,1469772903345/c1-hd-dn18.bdp.idc%2C16020%2C1469772903345.default.1470426151350 block BP-360285305-10.130.1.11-1444619256876:blk_1124743217_51010856] hdfs.DFSClient: Exception in createBlockOutputStream
java.io.IOException: Got error, status message , ack with firstBadLink as 10.130.a.b:50010
at org.apache.hadoop.hdfs.protocol.datatransfer.DataTransferProtoUtil.checkBlockOpStatus(DataTransferProtoUtil.java:140)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.createBlockOutputStream(DFSOutputStream.java:1334)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.(DFSOutputStream.java:1159)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.processDatanodeError(DFSOutputStream.java:876)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:402)
2016-08-06 03:44:29,321 WARN [DataStreamer for file /hbase/WALs/c1-hd-dn18.bdp.idc,16020,1469772903345/c1-hd-dn18.bdp.idc%2C16020%2C1469772903345.default.1470426151350 block BP-360285305-10.130.1.11-1444619256876:blk_1124743217_51010856] hdfs.DFSClient: Error Recovery for block BP-360285305-10.130.1.11-1444619256876:blk_1124743217_51010856 in pipeline DatanodeInfoWithStorage[10.130.x.x:50010,DS-b2197bf5-f129-44df-b569-3ba0e51772c4,DISK], DatanodeInfoWithStorage[10.130.x.x:50010,DS-b0dc4a29-30fe-4633-a292-79274279e345,DISK], DatanodeInfoWithStorage[10.130.a.b:50010,DS-abe5559f-f706-4309-983b-08dd30bcdca4,DISK]: bad datanode DatanodeInfoWithStorage[10.130.a.b:50010,DS-abe5559f-f706-4309-983b-08dd30bcdca4,DISK]RegionServer(DFSClient) 将 Bad DataNode 加入到一个不可用的队列 failed 中, 在向 NameNode 请求一个新的DataNode:
createBlockOutputStream:
while(pipeline创建没有成功 && pipeline没有被关闭 && dfsclient在被使用) {
//1, 如果有DataNode在写或者创建pipeline时出现问题,将出错的DataNode加入到不可用的队列中
failed.add(nodes[errorIndex]);
//2, 将有问题的DataNode从当前的pipeline中移除
//3, 是否需要往pipeline中添加新的DataNode节点
if(符合datanode的替换策略){
addDatanode2ExistingPipeline
}
//4, 生成新的generation stamp用以区分不同blk的不同版本
//5, 创建pipeline输入输出流
}
addDatanode2ExistingPipeline:
//get a new datanode
final DatanodeInfo[] original = nodes;
//nodes -> 目前pipeline上包含的DataNode节点
//failed -> 缓存不可用的DataNode的列表
//向NameNode请求新的DataNode
final LocatedBlock lb = dfsClient.namenode.getAdditionalDatanode(
src, fileId, block, nodes, storageIDs,
failed.toArray(new DatanodeInfo[failed.size()]),
1, dfsClient.clientName);
setPipeline(lb);在新添加DataNode节点日志文件中,发现由于该节点并没有block的相应的replica,而不能执行append的操作。这直接导致client创建新的pipeline失败。该DataNode被标记为 Bad DataNode , Client请求新的 DataNode 组建新的pipeline,append block操作失败,…, 直到hdfs集群范围内的 DataNode 被耗尽。
DFSClient在使用新的DataNode恢复pipeline之前,由于新加入的DataNode中并没有block的replica数据,首先会从原pipeline中选择一台DataNode作为src, 向src发送一个transfer blk到新DataNode的一个RPC请求:
//transfer replica
final DatanodeInfo src = d == 0? nodes[1]: nodes[d - 1];
final DatanodeInfo[] targets = {nodes[d]};
final StorageType[] targetStorageTypes = {storageTypes[d]};
transfer(src, targets, targetStorageTypes, lb.getBlockToken());由此,pipeline上所有的datanode都有blk,保证append操作能够继续进行。 那么,结合新DataNode抛出的异常,很明显, blk并没有被transfer到新的DataNode节点上。
在执行transfer操作的src datanode上,对应有这样的异常:
BP-360285305-10.130.1.11-1444619256876:blk_1124743217_51012555 to 10.130.a.b:50010 got
java.io.IOException: Need 96273147 bytes, but only 96270660 bytes available
at org.apache.hadoop.hdfs.server.datanode.BlockSender.waitForMinLength(BlockSender.java:475)
at org.apache.hadoop.hdfs.server.datanode.BlockSender.<init>(BlockSender.java:242)
at org.apache.hadoop.hdfs.server.datanode.DataNode$DataTransfer.run(DataNode.java:2116)
at org.apache.hadoop.hdfs.server.datanode.DataNode.transferReplicaForPipelineRecovery(DataNode.java:2866)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.transferBlock(DataXceiver.java:869)
at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.opTransferBlock(Receiver.java:168)
at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.processOp(Receiver.java:86)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.run(DataXceiver.java:251)
at java.lang.Thread.run(Thread.java:745)结合代码,可知:blk_1124743217 出现了[ack bytes] > [bytes on disk]的现象,造成这台DataNode无法向10.130.a.b transfer replica的问题。
当DFSClient每一次创建pipeline, 选择这台本身有问题的DataNode作为transfer source时, 那么在初始化pipeline输入输出流时(DataStreamer.createBlockOutputStream), 由于之前的transfer操作失败,pipeline上有些DataNode并没有block的replica,因此writeBlock操作并不能在pipeline所有的DataNode上顺利执行,pipeline创建失败。这样的现象类似于HDFS-6937,只不过因不同,结果类似。
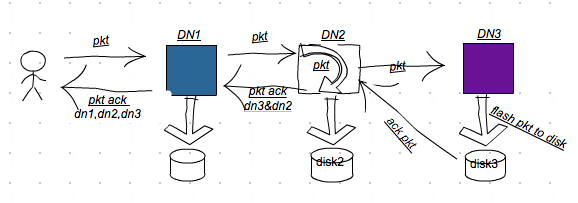
现在问题变成,为什么在DN2(暂且称之为)中, 出现 blk_1124743217 出现了[ack bytes] > [bytes on disk]的现象。 最初的pipeline为: client -> DN1 -> DN2 -> DN3。 在DN2中,由于其并非为pipeline中最后一个datanode, RegionServer 中默认使用了hflush的方式来写入WAL, 所以当DN2接收到DN1的packet数据包(pkt)时,就将该pkt加入到等待ack的队列中。
BlockReceiver#receivePacket:
// put in queue for pending acks, unless sync was requested
if (responder != null && !syncBlock && !shouldVerifyChecksum()) {
((PacketResponder) responder.getRunnable()).enqueue(seqno,
lastPacketInBlock, offsetInBlock, Status.SUCCESS);
}接着将pkt写入到DN3中, 最后,将pkt(data+checksum)写入到对应的文件中。并更新block replica [bytes on disk]的数据指标:
/// flush entire packet, sync if requested
flushOrSync(syncBlock);
replicaInfo.setLastChecksumAndDataLen(offsetInBlock, lastCrc);当DN2 PacketResponder接收到DN3的pkt ack数据时,更新block replica的[ack bytes]的数据指标:
PipelineAck replyAck = new PipelineAck(seqno, replies,
totalAckTimeNanos);
if (replyAck.isSuccess()
&& offsetInBlock > replicaInfo.getBytesAcked()) {
replicaInfo.setBytesAcked(offsetInBlock);
}其中, DN2将pkt写入到存储介质中与DN2接收DN3的ack数据,这两个过程是异步的。 也就是,可能在某一时刻,出现类似于“[ack bytes] > [bytes on disk]”的现象。
在DN2日志中,有这样的一个异常:
2016-08-06 03:44:26,172 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Exception for BP-360285305-10.130.1.11-1444619256876:blk_1124743217_51010856
java.nio.channels.ClosedByInterruptException
at java.nio.channels.spi.AbstractInterruptibleChannel.end(AbstractInterruptibleChannel.java:202)
at sun.nio.ch.FileChannelImpl.position(FileChannelImpl.java:268)
at org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl.adjustCrcChannelPosition(FsDatasetImpl.java:1479)
at org.apache.hadoop.hdfs.server.datanode.BlockReceiver.adjustCrcFilePosition(BlockReceiver.java:985)
at org.apache.hadoop.hdfs.server.datanode.BlockReceiver.receivePacket(BlockReceiver.java:677)
at org.apache.hadoop.hdfs.server.datanode.BlockReceiver.receiveBlock(BlockReceiver.java:849)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.writeBlock(DataXceiver.java:804)
at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.opWriteBlock(Receiver.java:137)
at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.processOp(Receiver.java:74)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.run(DataXceiver.java:251)
at java.lang.Thread.run(Thread.java:745)从日志中,DN2在写入blk_1124743217 pkt过程中,被无情中断,这直接导致DN2无法更新blk_1124743217的[bytes on disk]的数据指标,造成了数据的永久丢失。
DN2只有完成以下这些步骤后,才准备接收下一个pkt:
- enqueue pkt ack to waiting queue.
- flush pkt to downstream datanode.
- flush pkt to disk file.
while (receivePacket() >= 0) { /* Receive until the last packet */ }DN2抛出 java.nio.channels.ClosedByInterruptException 异常时, Client为blk_1124743217建立的pipeline失败,从日志上分析,此后DN2上的blk_1124743217便不在有成功的数据写入操作。因此, 出现“[ack bytes] > [bytes on disk]”的现象时间可确定为在”2016-08-06 03:44:26“之前。
对于上述的案例来说,设pkt是原pipeline中最后被成功的ack的packet,按照DFSClient的逻辑,该pipeline至少有另一个packet正在写或已在pipeline上,将其标记为pkt0.(pkt并非block最后一个packet,而且上游持续有数据写入.)
假设DN2上中断的异常属于pkt0。
pkt0被DN3接收之后,在DN3由于TimeOutException关闭之前将pkt0 ack数据发送给DN2, DN2接收到这样的数据之后,更新block ack bytes指标, 再将DN2和DN3的ack数据打包一起发给DN1. 要使pkt成为最后一个被成功ack的packet,且DN2出现 ack bytes > bytes on disk的现象, 则可能有以下几种情况:
- DN2未将pkt0 ack数据发送给DN1。 那么存在这样的关系: a1 < a2, a1 为DN1的ack bytes指标; a2为DN2的ack bytes的指标。在后来的DataNode stream recovery操作中, 显示a1=a2, 这样的情况被排除。
- DN1未将pkt0 ack数据发送给Client。那么DN1将会被Client标记成要替换的DataNode,而并非DN3了,而且Client重建pipeline的原因也是因为DN3的SocketTimeoutException,该信息沿ack传递路径经DN2 -> DN1传递给Client,Client才知道DN3出了问题。
因此,可以下一个这样的结论:在DN2上中断的pkt一定是原pipeline中最后一个被成功ack的packet。
这个结论很重要,可以大致得到pipeline(DN1->DN2->DN3)出现问题那一刻DN2处理pkt时线程栈的情况,在BlockReceiver#receivePacket方法中,往DN3写入pkt之后,adjustCrcFilePosition()方法之前,是没有比较耗时操作的。因此,DN2当时栈的情况应该是:
at java.nio.channels.spi.AbstractInterruptibleChannel.end(AbstractInterruptibleChannel.java:202)
at sun.nio.ch.FileChannelImpl.position(FileChannelImpl.java:268)
at org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl.adjustCrcChannelPosition(FsDatasetImpl.java:1479)
at org.apache.hadoop.hdfs.server.datanode.BlockReceiver.adjustCrcFilePosition(BlockReceiver.java:985)
at org.apache.hadoop.hdfs.server.datanode.BlockReceiver.receivePacket(BlockReceiver.java:677)
at org.apache.hadoop.hdfs.server.datanode.BlockReceiver.receiveBlock(BlockReceiver.java:849)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.writeBlock(DataXceiver.java:804)
at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.opWriteBlock(Receiver.java:137)
at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.processOp(Receiver.java:74)
at org.apache.hadoop.hdfs.server.datanode.DataXceiver.run(DataXceiver.java:251)
at java.lang.Thread.run(Thread.java:745)由于DN2一直陷入文件寻址的过程中(处理pkt),造成DN2无法处理pkt0,进而无法将pkt0写入到DN3中,当超过60s时(rpc timeout),DN3率先抛出SocketTimeoutException异常,将属于pipeline的socket资源关闭,在DN2接收下游DN3上的ack数据线程抛出异常。
DN3:
2016-08-06 03:44:22,981 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Exception for BP-360285305-10.130.1.11-1444619256876:blk_1124743217_51010856
java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/DN3:50010 remote=/DN2:43529]
at org.apache.hadoop.net.SocketIOWithTimeout.doIO(SocketIOWithTimeout.java:164)
at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:161)
at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:131)
at java.io.BufferedInputStream.fill(BufferedInputStream.java:246)
at java.io.BufferedInputStream.read1(BufferedInputStream.java:286)
at java.io.BufferedInputStream.read(BufferedInputStream.java:345)
at java.io.DataInputStream.read(DataInputStream.java:149)
at org.apache.hadoop.io.IOUtils.readFully(IOUtils.java:199)
at org.apache.hadoop.hdfs.protocol.datatransfer.PacketReceiver.doReadFully(PacketReceiver.java:213)
at org.apache.hadoop.hdfs.protocol.datatransfer.PacketReceiver.doRead(PacketReceiver.java:134)
at org.apache.hadoop.hdfs.protocol.datatransfer.PacketReceiver.receiveNextPacket(PacketReceiver.java:109)
at org.apache.hadoop.hdfs.server.datanode.BlockReceiver.receivePacket(BlockReceiver.java:472)
at org.apache.hadoop.hdfs.server.datanode.BlockReceiver.receiveBlock(BlockReceiver.java:849)DN2:
2016-08-06 03:44:22,982 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder: BP-360285305-10.130.1.11-1444619256876:blk_1124743217_51010856, type=HAS_DOWNSTREAM_IN_PIPELINE
java.io.EOFException: Premature EOF: no length prefix available
at org.apache.hadoop.hdfs.protocolPB.PBHelper.vintPrefixed(PBHelper.java:2280)
at org.apache.hadoop.hdfs.protocol.datatransfer.PipelineAck.readFields(PipelineAck.java:244)
at org.apache.hadoop.hdfs.server.datanode.BlockReceiver$PacketResponder.run(BlockReceiver.java:1237)
at java.lang.Thread.run(Thread.java:745)PBHelper.vintPrefixed:
public static InputStream vintPrefixed(final InputStream input)
throws IOException {
final int firstByte = input.read();
if (firstByte == -1) {
throw new EOFException("Premature EOF: no length prefix available");
}DN2的PacketResponder收到DN3的异常消息之后,将DN3这台DataNode标记为Error,并reply给DN1, DN1将错误信息打包后交给Client:
if (ack == null) {
// A new OOB response is being sent from this node. Regardless of
// downstream nodes, reply should contain one reply.
replies = new int[] { myHeader };
//这里mirrorError = true;
} else if (mirrorError) { // ack read error
int h = PipelineAck.combineHeader(datanode.getECN(), Status.SUCCESS);
int h1 = PipelineAck.combineHeader(datanode.getECN(), Status.ERROR);
replies = new int[] {h, h1};
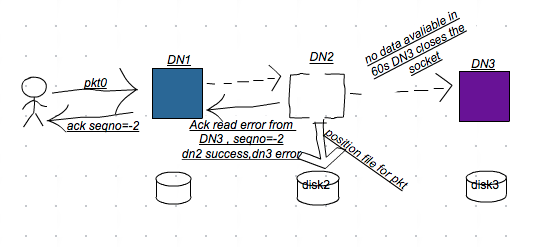
}Client解析DN1传来的ack信息(seqno=-2), 发现DN3对应的ack状态为Error的,Client将DN3标记为一个不可用的_DataNode_, 并将对应的ResponseProcessor线程关闭,
// if the Responder encountered an error, shutdown Responder
if (hasError && response != null) {
try {
response.close();
response.join();
response = null;
} catch (InterruptedException e) {
DFSClient.LOG.warn("Caught exception ", e);
}在DataStreamer主线程上,将原来的pipeline关闭,将待ack的pkt0移到要发送的队列队首中,重新选择DataNode(放弃DN3)建立pipeline. 在恢复pipeline的过程中,使用DN2作为transfer source, 而原来DN2中的replica是有问题的(数据丢失), 这样便造成新的pipeline无法创建成功。可以预估DN2 position file操作大概所花的时间约为1min。
总结一下过程,
1, Client flushes pkt to pipeline and gets succuss acks from DN1. Stage -> BlockConstructionStage.DATA_STREAMING
2, Client flushes next pkt(pkt0) to pipeline and timeout from DN3. DN2 sends the error ack to DN1.
3, Client close current pipeline and choose DN4 to replace DN3, and transfer blk from DN2 to DN4. ![]()
4, Create new pipeline with DN1, DN2 and DN4. Stage-> BlockConstructionStage.PIPELINE_SETUP_STREAMING_RECOVERY
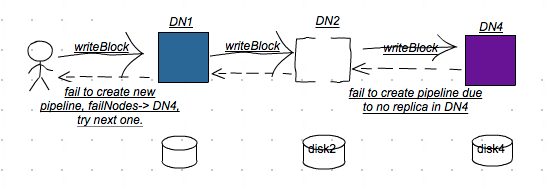
同时,通过分析,在往新的pipeline添加DataNode时,尽管DataNode在tranfer block过程中发生IOException(例如本例的例子), 然而Client是感知不到的,继续使用有问题的DataNode(数据已发生丢失)以及新DataNode重建pipeline。这样的话,在往pipeline写入数据时,是不会成功的。在符合DataNode替换策略的前提下,Client会尝试选择与HDFS集群范围内所有可用的DataNode建立一条pipeline,直到无DataNode可用为止。 文中描述的异常场景按照pipeline读写逻辑是很难发生的,然而不同的软硬件环境,不同的读写压力等等,这些都为软件的测试和编写带来一定的局限性,也给程序的健壮性带来一些挑战。以文中为例,当发现无可用的DataNode时,RegionServer将会异常退出。在分布式环境下,调试和定位问题变得复杂和不确定,随着深入,假设不断的被推翻和修正,这些都有赖于日志和源码的分析。
如何解决
1, 提高hdfs rpc读写的超时时间.
对于第一种解决方案来说,更改涉及到Client端(RegionServer), 同时还需要重启集群内的_DataNode_服务。这种方案修改简单,然而对于集群容错和排错来说并非最佳,同时将这个值设置为多大比较合适,则需要更全面的测试和评估。
2, 修改客户端,在恢复pipeline,将replica移动到新的datanode之间,使用原pipeline最后一台_DataNode_作为source。
根据设计:
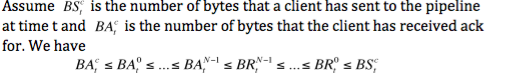
在这里, BA(i, t)表示在任意时刻t,pipeline第i台 DataNode acked bytes的指标, i的大小代表离Client的远近;BR(i,t)表示在任意时刻t,pipeline第i台 DataNode received bytes的指标, i的大小代表离Client的远近. 假设原pipeline中最后一台_DataNode_, acked bytes指标记为BAD, received bytes指标记为BR; 对应的Client, acked bytes记为 BAC, 发送的字节数记为BS。则,存在这样的不等式关系: BAC <= BAD <= BR <= BS。
在pipeline最后一台_DataNode_中,当且仅当DataNode完成packet数据checksum校验以及将packet flush到磁盘时,才更改BAD的数据指标。 由此,replica BAD的数据已定具有一下性质: 1, replica data与checksum匹配; 2,replica data acked bytes <= data on disk bytes.
在恢复pipeline时, Client将等待ack的数据重新归置到待发送到队列中,即(BAC, BS], 从原pipeline最后_DataNode_上拷贝的数据区间在(0, BAD]或者 (0, BR], 新选择的_DataNode_ replica无论是在(0, BAD]或(0, BR], 都能正确的接收来自Client从BAC位置开始发送过来的数据。
假设原pipeline最后的一台_DataNode_不可用怎么办? 如shutdown, abort, replica被删除等等,那么采取的策略是随机从pipeline剩余的_DataNode_作为新加入_DataNode_的transfer source.
同样,该方案也有明显的缺点,如果发生在不同机架上的数据拷贝,那么这样的方案将会对pipeline的快速恢复有一定的消极影响。 但如果_DataNode_在同一rack内,则完全有理由这么做。从理论上来说,block的多备份机制是为了减少各种故障导致数据异常而采取的一种方案,然而,这并不意味着数据会一直正常下去,在某些情况下,采用方案2也未能防止数据的完整正确性, 例如: 按照描述, 当DN1和DN2同时出现data acked bytes > data on disk bytes现象,而此时DN3不可用时,也会出现类似于文中描述的问题。